OptMatch
This is the detail page of the paper
OptMatch: Optimized Matchmaking via Modeling the High-Order Interactions on the Arena
accepted by KDD2020 ADS Oral
1. Introduction
Authors:
@LinxiaGong(巩琳霞), @XiaochuanFeng(冯小川), @DezhiYe(叶徳志)*, @LiHao(李浩)
@RunzeWu(吴润泽), @JianrongTao(陶建容), @ChangjieFan(范长杰), @PengCui(崔鹏)
*The work was done during the internship.
Keywords: Game Matchmaking, User Engagement, Graph Embedding
Long Story Short
This paper gives:
-
An generalized iterative two stage data-driven matchmaking framework, namely OptMatch, which has minimal product knowledge and data required, by utilizing only win/lose/score results of matches;
- (stage 1) offline learning:
- extracts two interpersonal relations for representing and understanding tacit coordination interactions among players;
- learns the representation vectors to incorporate the high-order interactions;
- trains a model(i.e., OptMatch-Net) to encode team-up effect and predict the match outcome;
- (stage 2) online planning:
- leverages the representation vectors of players and OptMatch-Net model to maximize the (predicted) gross utilities for the queuing players
Advantages:
- applicable to most of gaming products, fast and easy to implement
- minimal knowledge about the products and data required
- robust to data drift
Limitations:
- (for online games and e-sports) a hero can appear at maximun once in a team
It’s worth noting:
- this method is complementary to user portrait
2. Matchmaking System: OptMatch
2.1 System Overview
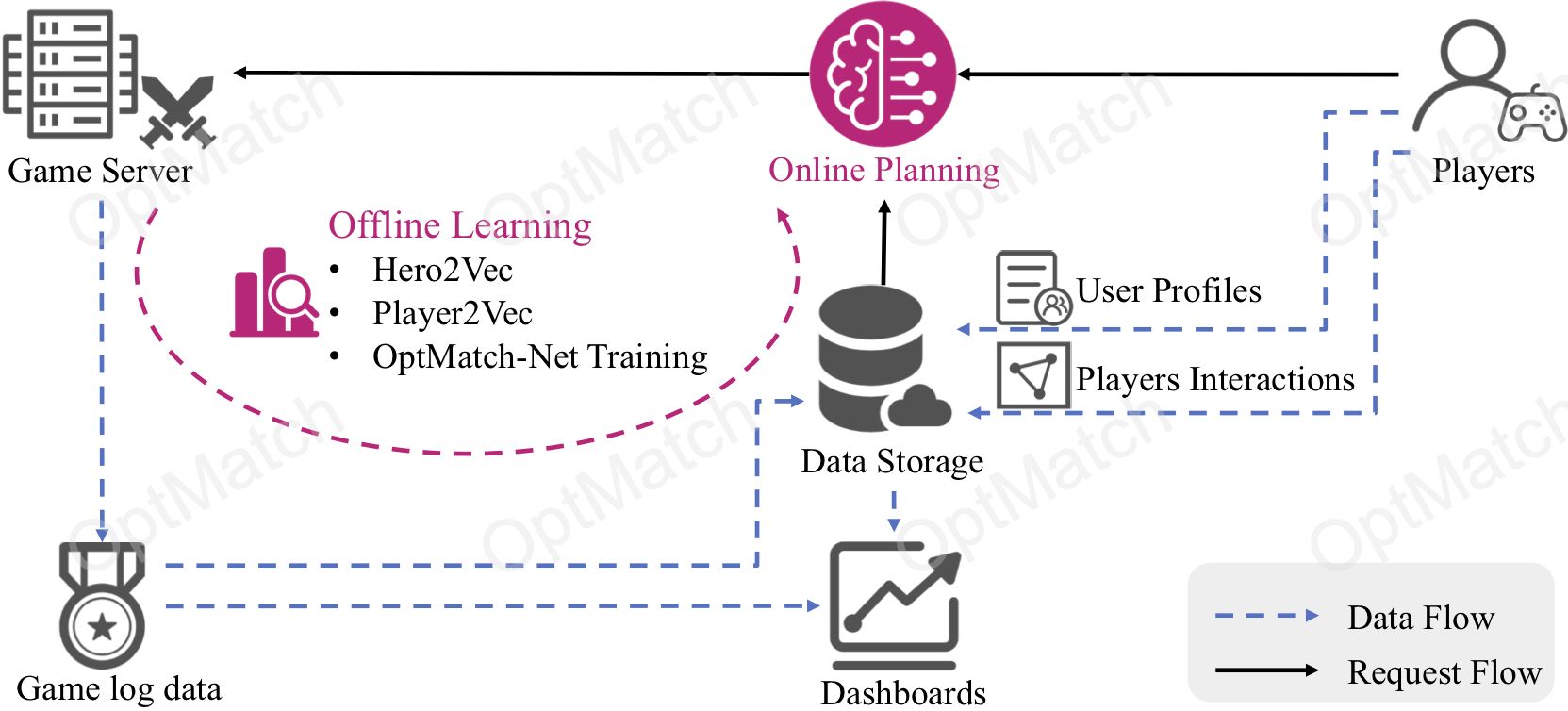
2.2 Offline Learning
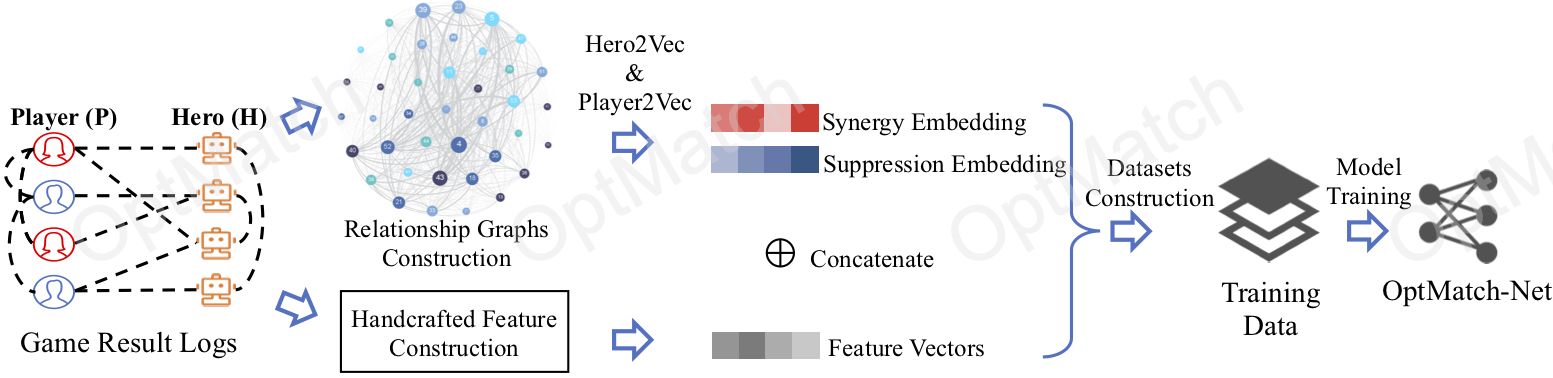
2.2.1 Relationship Mining
2.2.2 OptMatch-Net
Secondly, a neural network (i.e. OptMatch-Net) is used to learn the intra-team interactions with a self-attention based Team2Vec Layer, and learn the inter-team interactions with a TeamComparison Layer.
Intra-team interaction (Team-up effect): each player can be beneficial/ disadvantageous to other team members
Inter-team interaction (Rock-paper-scissors effect): there might be no absolute measure to rank strengths of the teams
2.3 Online Planning

3. Experiments Details (Updating)
3.1 Datasets
» View the details and analysis of the datasets or view the detail page of the dataset through the dataset name (in the following table).
| Dataset | Matches | Heroes | Players |
|---|---|---|---|
| Dota2 (5v5) | 50,000 | 113 | 10,815 |
| LOL (5v5) | 623,263 | 145 | / |
| LOL Championship (5v5) | 187,588 | 139 | 43,706 |
| NBA | 3,342 | / | 949 |
| Fever Basketball (3v3) | 851,648 | 40 | 33,873 |
Dataset Split: Matches are sorted by the time for each dataset. Then we take the first 80% matches as the training set and the remaining 20% matches as the test set. Why? This ensures no leak of result information from the test set.
3.2 Codes structure
src
├── data_analysis
| └── hero_combination_analysis.py
├── experiments
├── graph_embedding
│ └── ge_optmatch.py
├── models
│ └── optMatch-Net.py
├── requirements.txt
└── utils
3.3 Experiment Example
3.4 Online A/B Test Result
4. Discussion
4.1 Players’ Utility (Players’ Engagement)
Matchmaking aims to maximize the gross utility (i.e. satisfaction/engagement) of players.